I’ve recently looked at Variational Autoencoders (VAE). It can be used for dimension reduction or data generation. I usually have a hard time going through the analytics, so I’ve used geometry to view it.
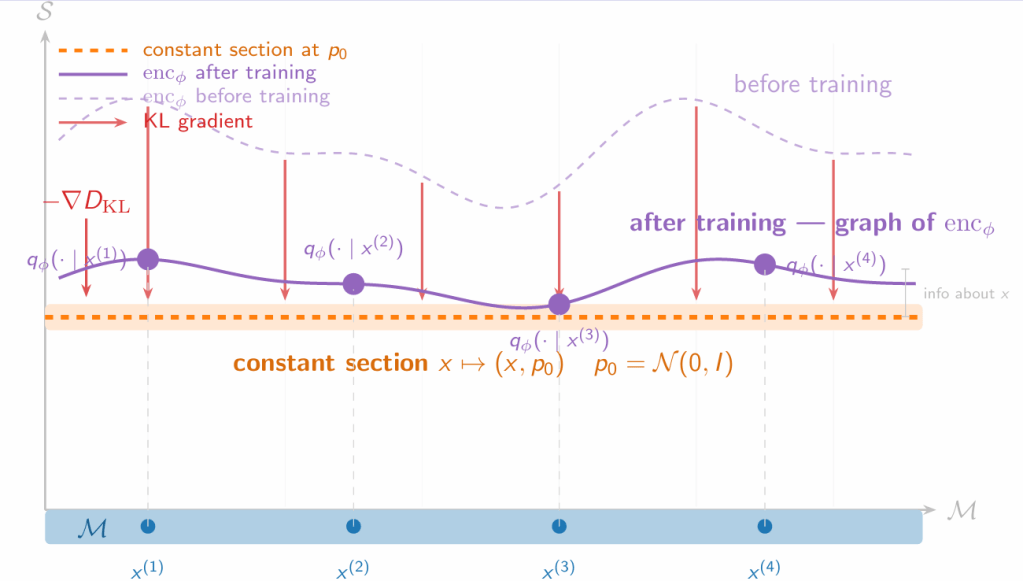
The idea is pretty darn clever. To make things concrete, let’s assume we have many images of people’s faces. Each face can be viewed as a 30,000-dimensional vector. We map each image to a Gaussian blob, viewed as a point in the statistical manifold S consisting of Gaussian blobs where the variances are diagonal. We have a fiber bundle from S -> M. We wish to construct the section (a map) from M -> S. We want this map to be as close as possible to the constant section M -> {N(0.I)}. However, we need the data points to be distinct from each other so that we can reconstruct them.
See the original paper here on ArXiv.

Leave a comment